TL; DR
-
Fine-tuning SDXL UNET with high-quality datasets can enhance the AES score of generated images, but there is a limitation to this improvement. Specifically, you can easily upgrade the AES score of SDXL-base, which is initially aesthetically evaluated as 6.0, to reach a score of 6.7. However, a further enhancement in the AES score becomes significantly limited, even tuning on a high-quality dataset whose average AES score exceed 7.5 with many steps.
-
High-quality fine-tuning can negatively affect text fidelity.
-
Fine-tuning UNET without incorporating high-level noise latent features can enhance text fidelity in trade with a slight decrease in aesthetic quality
-
A self-reward SDXL-DPO pipeline can both benefit text fidelity and aesthetic quality
Background
high-quality fine-tuning
It is widely known that fine-tuning SDXL using a carefully curated set of aesthetically pleasing data can significantly enhance the quality of SDXL’s output. In the EMU paper, the authors assert that quality tuning can effectively enhance the pretrained base model, similar to how we do supervised fine-tuning with a Language Model (LLM).
The EMU paper has provided a good fine-tuning recipe for aesthetic alignment as follows:
-
2k highly visually appealing images
-
a small batch size of 64
-
noise-offset is set to 0.1
-
no more than 15K iterations regardless of loss decreasing
However, it’s worth noting that the EMU paper hid certain crucial details regarding this recipe. For instance, it doesn’t show us any samples from the 2,000 images to let us know how appealing these images are, the choice of the optimizer, and the criteria for determining when to early stop the fine-tuning process.
SDXL-DPO
If you download a highly-rated checkpoint from Civitai and use it to create an image, you’ll likely find it a bit tricky to generate an image that can follow detailed textual descriptions. This issue is likely because these checkpoints are overfitted on a curated dataset. Considering the fact that it is really hard to find when to early stop the training, the checkpoints are easily overfitted and harm the text fidelity.
To address such an issue, a promising solution is to push the diffusion models towards high text fidelity with Diffusion-DPO. Diffusion-DPO enhances the training target for SDXL besides MES loss of predicting noises by incorporating a rewarding loss without the need for an online rewarding model. However, the efficacy of DPO in fixing text fidelity largely depends on the quality of the preference data pairs. What’s worse, it is hard to find any reliable metrics to determine whether SDXL-DPO can fix the text fidelity without sacrificing aesthetic quality.
Self-Rewarding
Recently, in this paper, Meta researchers showed that using an iteratively updated model, which generates its own rewards during training, can significantly enhance the instruction following ability when compared to a frozen reward model during SFT. What’s particularly surprising is that by fine-tuning Llama 2 70B through only three iterations of this self-rewarding approach, they achieved a model that outperforms several closed-source LLMs, including Claude 2, Gemini Pro, and even GPT-4 0613. This finding has inspired me to incorporate this concept into the SDXL-DPO pipeline to explore the potential benefits for image generation.
Method
Following the idea of Self-Rewarding, I change the SDXL-DPO pipeline by introducing a slowly updated reference UENT based on EMA.
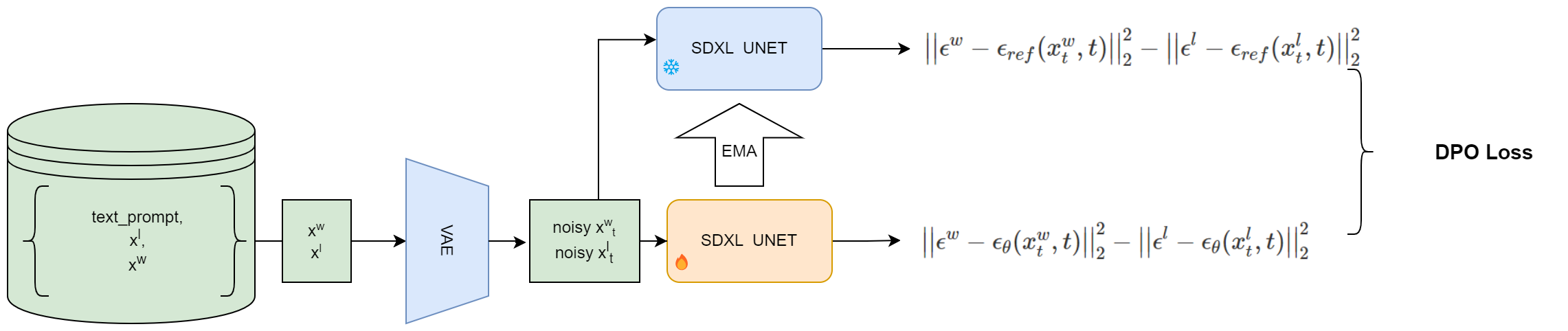 Figure 1. A Self-Reward SDXL pipeline with EMA updated reference UNET; \(x^w\) and \(x^l\) represents a preferred image and a non-preferred image with the same text prompt. \(x^w_t\), \(x^l_t\) means adding noises to \(x^w\) and \(x^l\) at a random timestep \(t\) respectively;
Figure 1. A Self-Reward SDXL pipeline with EMA updated reference UNET; \(x^w\) and \(x^l\) represents a preferred image and a non-preferred image with the same text prompt. \(x^w_t\), \(x^l_t\) means adding noises to \(x^w\) and \(x^l\) at a random timestep \(t\) respectively;
Experiments
Let’s start with a fine-tuned proprietary SDXL-base as our baseline. I gathered 20 carefully selected prompts from PromptHero, which are quite challenging for SDXL-base to generate visually pleasing images with only one-shot, as our benchmark. Each of these prompts was used to create 4 images using the same random settings and was refined with SDXL-refiner. Then, I employed LAION-Aesthetics V2 to calculate the average aesthetic scores for a total of 80 generated images. This evaluation helps us determine whether the checkpoints learns to yield more visually pleasing images after fine-tuning.
The high-curated dataset \(D\) was filtered from 4M MidJourney v5 dataset. Since the raw image prompts are not natural language, I regenerated captions for each image using LLaVA-v1.5-13B. Various filters, such as OCR, SigLIP, and an aesthetic evaluator, were applied to curate the data. As a result, I obtained a 2k text-image pairs, with an average aesthetic score of 7.62.
The experiment are conducted with 8 x A800, batch_size = 64, using deepzeros-2
| id |
avg aes score |
note |
| baseline |
6.7 |
a fine-proprietary SDXL checkpoint fine-tuned from SDXL-base |
| trail 1 |
6.7413 |
the best aes score picked from all fine-tuned checkpoints in 10 epochs |
| trail 2 |
6.7515 |
the best aes score picked from all fine-tuned checkpoints in 50 epochs |
| trail 3 |
6.7420 |
continual DPO fine-tuned from the last saved checkpoint (epoch 10 step 300) in trail 1 |
Table 1: Experiments of fine-tuning a proprietary SDXL checkpoint whose generated images can achive average aesthetic score of 6.7 under our benchmark; Please check appendix for more training configuration details.
It’s worth noting that even if the curated dataset was intentionally fine-tuned for 50 epochs and has an average aesthetic score exceeding 7.5, the baseline checkpoint is still hard to overfit on the dataset and the AES score is only increased from 6.7 to 6.75.
ShowCase
The following analysis is based on a cherry-picked example to visualize how different training strategies can directly impact the generated results. To further validate these findings, additional trials are necessary. I leave this task for me in the future or those who are interested in digging it further.
 Figure 2. A comparison of generated results under different training settings following Table 1. All images are generated with the same configurations. Please check appendix for more config details.
Figure 2. A comparison of generated results under different training settings following Table 1. All images are generated with the same configurations. Please check appendix for more config details.
According to Figure 2, we can observe that:
-
(a) Baseline; it tends to generate images in watercolor style. The light and contrast is unrealistic. The right-side image in (a) fails to include “the cape of the world” mentioned in the prompt;
-
(b) Trail 1, fine-tuned from baseline with 2k high-quality dataset, can generate more aesthetic images, especially the lighting;
-
(c) Trail 2, fine-tuned with the same configuration as Trail 1 but more steps, ignores the “cape”, yet it retains the lighting and art-style as Trail 1;
-
(d) The image on the right closely resembles the baseline, particularly the background clouds. It seems to blend the watercolor and realism. The model also successfully draws the “Cape”, which suggests that DPO could restore the text fidelity that may have been broken during high-quality fine-tuning in previous steps.
Appendix
training recipe for trail 1 and trail 2
grad_accumulate: 4
grad_clip: 5.0
# optimizer config
weight_decay: 0.01
optimizer_type: "adamw"
lr: 1e-6
adam_beta1: 0.9
adam_beta2: 0.999
adam_weight_decay: 1e-2
adam_epsilon: 1e-8
scheduler:
scheduler_type: "cosine"
warmup_steps: 200
noise_offset: 0.0357
input_perturbation: 0.0
Generation config for Figure 2
prompt: An old man waiting for the end of his life at the cape of the world
inference: fp16
resolution: 1024
gs: 5.0
sampling_method: DPMkarras
random_seed: 100